
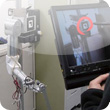
エージェントによる行動学習は,行動選択→評価→パラメータの調節という一連の流れを繰り返すことで行う.その際,エージェントがとりうる全ての状態に対して事前に正しく評価関数を設計できることが理想的であるが,現実的には困難です.
そこで我々は,行動学習を行うエージェントに対して人間の教示者が適切に介在する方法として,教示者が直接正しい動作を教示入力として与えるのではなく,主観的かつ曖昧な評価を,エージェントを動作させながらオンラインでかつ非同期に与えることによって学習を望ましい方向に誘導する,人間にとって直観的な対話的行動学習の枠組みを提案しています.これを,従来のロボットティーチングとは区別して,(ロボット) コーチングと称する.
ここでは,人間の教示者がエージェントの報酬関数を状況に応じて更新することを目的として直接的に介入し,これに基づいてエージェントが状態価値を学習する新しいヒューマン・エージェント・インタラクションの枠組みを提供するものでる.これは,従来独立して行われていたエージェントによる行動学習と,人間による事前の報酬設計の作業を並行して,かつオンラインで行うための手法であり,エージェントの学習を支援すると共に,設計者による事前の報酬設計の負担を軽減することもできると考えられる.また教示者によるコーチングに,「良い・悪い」というプリミティブな評価を用いることで,機械学習についての専門的な知識や特殊なインタフェースを必要とせず,さらにタスクや実験環境にも依存しない,直感的で簡便なインタラクションの実現を目指しています.
年度: 2008-
メンバー:
廣川 暢一
鈴木 健嗣
共同研究:
民間企業(自動車)
Tags:
- 認知ロボティクス
- 次世代知能化技術
![]()
本研究の一部は,文部科学省科学研究費補助金の支援を受けて行われております.
|
|
|
|
![]()

 痛みを知覚するロボット
痛みを知覚するロボット 視聴力覚の協調に基づく能動的な物体理解
視聴力覚の協調に基づく能動的な物体理解 ロボットとの社会的インタラクション研究
ロボットとの社会的インタラクション研究 認知ロボットのためのソフトウエア研究
認知ロボットのためのソフトウエア研究 楽器演奏ロボット
楽器演奏ロボット 話すために言語を学ぶ学習機構
話すために言語を学ぶ学習機構 人形型インタフェースの研究
人形型インタフェースの研究 人とロボットによる関係のデザイン
人とロボットによる関係のデザイン